Architecture et composants de la plateforme
TDP est une plate-forme de gestion de données open source qui fournit un ensemble complet d’outils et de services pour le stockage, le traitement et l’analyse de grands ensembles de données. Il est construit sur l’écosystème Apache Hadoop et d’autres projets open source, et il permet aux organisations de gérer efficacement leurs traitements Big Data.
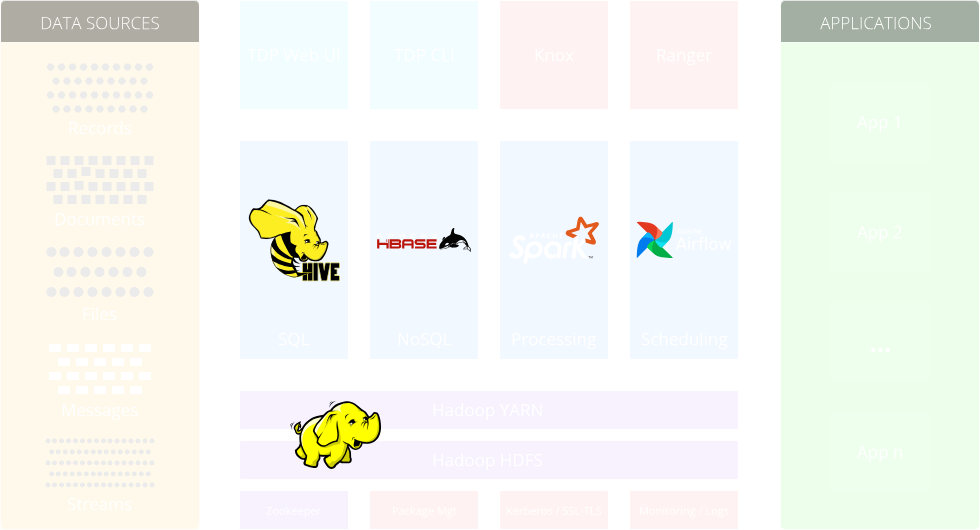
Composants du socle
Apache Hadoop HDFS
HDFS (Hadoop Distributed File System) est un système de stockage distribué qui fournit un moyen fiable et évolutif de stocker et de gérer de grandes quantités de données sur plusieurs machines dans un cluster Hadoop. Il décompose les données en blocs et les réplique sur différents nœuds pour assurer la tolérance aux pannes et optimiser les performances.
Apache Hadoop YARN
YARN (Yet Another Resource Negotiator) est un système de gestion des tâches qui permet une utilisation efficace des ressources dans un cluster Hadoop. Il agit en tant que composant central responsable de la gestion et de l’allocation des ressources à divers frameworks de traitement de données, tels que Spark, MapReduce et Flink, leur permettant la distribution des traitements et l’utilisation efficace des ressources disponibles.
Apache Hive
Hive est une infrastructure d’entrepôt de données construite sur Hadoop. Il repose sur le langage de requête SQL (HiveQL) et permet aux utilisateurs d’effectuer des requêtes et des analyses ad hoc sur les données stockées dans Hadoop.
Apache Spark
Spark est un moteur de calcul distribué, rapide et polyvalent qui fournit des capacités de traitement de données en mémoire. Il prend en charge différents cas d’usage telles que le traitement par batch, le streaming en temps réel, l’apprentissage automatique et le parcours de graphes.
Apache HBase
HBase est une base de données NoSQL distribuée, évolutive et cohérente qui gère de grandes quantités de données structurées. Il permets des accès aléatoires en lecture et en écriture aux données stockées dans HDFS.
Apache Zookeeper
ZooKeeper est un service de coordination centralisé open source qui fournit une infrastructure fiable pour les systèmes distribués. Il offre un moyen simple et robuste de gérer et de synchroniser les informations de configuration, les services de nommage et les verrous dans un environnement distribué. ZooKeeper aide à assurer la cohérence, la fiabilité et la tolérance aux pannes dans les applications distribuées en maintenant une vue cohérente et à jour de l’état du système.
Composants de sécurité
Apache Knox
Knox sert de passerelle sécurisée pour les clusters Hadoop et d’autres systèmes de Big Data. Il agit comme un reversed-proxy, fournissant un point d’entrée unifié pour accéder aux ressources du cluster. Il offre des fonctionnalités telles que la fédération d’identité, le chiffrement SSL/TLS, l’authentification et les mécanismes d’autorisation pour protéger le cluster contre tout accès non autorisé.
Apache Ranger
Ranger est une infrastructure de sécurité complète conçue pour Hadoop et d’autres écosystèmes Big Data. Il fournit une administration centralisée pour la gestion des règles de sécurité et un contrôle d’accès précis pour assurer la protection et la confidentialité des données. Avec Ranger, les administrateurs définissent et gèrent les politiques de sécurité, les listes de contrôle d’accès (ACL) et le contrôle d’accès basé sur les rôles (RBAC). Il offre des fonctionnalités avancées telles que le filtrage à l’échelle des lignes et le masquage dynamique des données en fonction des autorisations des utilisateurs. De plus, Ranger fournit des capacités d’audit et de surveillance, permettant aux organisations de suivre les activités des utilisateurs et de maintenir la conformité réglementaire.
Composants additionnels
Apache Kafka
Kafka est une solution open source distribuée permettant la gestion et le traitement des flux de données en temps réel. La solution permet la collecte, le stockage et le traitement des données de streaming avec des volumes à haut débit, tout en étant tolérante aux pannes et évolutive. Kafka simplifie le processus de création de pipelines de données, permettant une intégration de données fiable entre différents systèmes et applications.
Apache Hue
Hue est une interface Web open source qui simplifie la gestion et l’interaction avec les outils de l’écosystème Hadoop. Il fournit un environnement convivial pour accéder et travailler avec divers composants tels que HDFS, Hive, HBase, etc., permettant aux utilisateurs de naviguer facilement et d’effectuer des tâches de traitement, de requêtage et d’analyse de données sans nécessiter de connaissances approfondies en ligne de commande.
Jupyter Hub
Jupyter Hub est un projet open source qui permet un accès multi-utilisateurs aux notebooks Jupyter. Il fournit une interface Web permettant aux utilisateurs de créer et de gérer leurs propres instances de bloc-notes Jupyter, permettant une analyse, une visualisation et une programmation collaboratives et interactives des données dans divers langages tels que Python, R et Julia.
Apache Livy
Livy est un service Web RESTful open source qui facilite l’exécution et la gestion à distance des tâches Apache Spark. Il fournit une interface pratique pour soumettre, surveiller et contrôler les applications Spark, prenant en charge plusieurs langages de programmation.