Components architecture
Overview
TDP is an open-source data management platform that provides a comprehensive set of tools and services for storing, processing, and analyzing large datasets. It is built on top of the Hadoop ecosystem and other open-source projects, and it enables organizations to effectively manage their big data workloads.
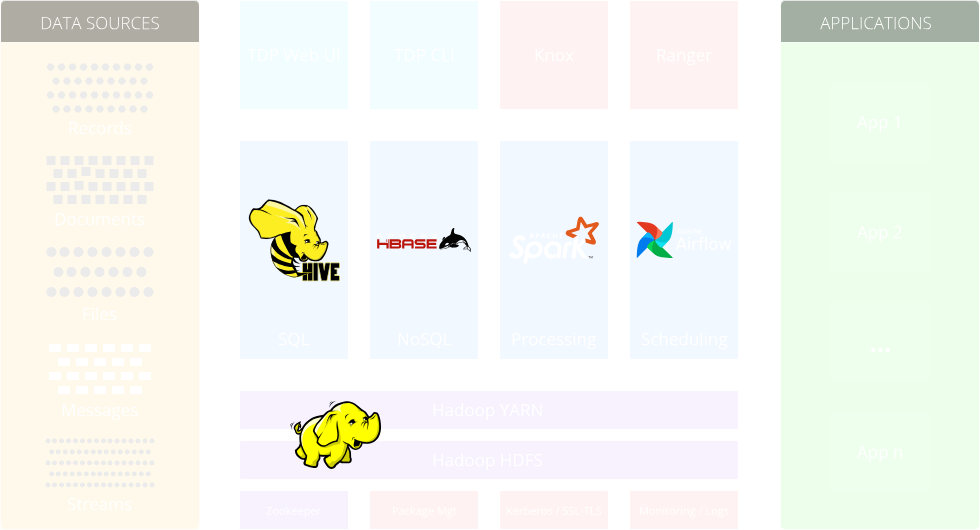
Key components
Apache Hadoop HDFS
HDFS (Hadoop Distributed File System) is a distributed storage system that provides a reliable and scalable way to store and manage large amounts of data across multiple machines in a Hadoop cluster. It breaks down data into blocks and replicates them across different nodes for fault tolerance and efficient data processing.
Apache Hadoop YARN
YARN (Yet Another Resource Negotiator) is a cluster resource management system that allows for efficient utilization of resources in a Hadoop cluster. It acts as the central component responsible for managing and allocating resources to various data processing frameworks, such as Spark, Hive, and Flink, enabling them to run concurrently and effectively utilize the available cluster resources for executing data processing tasks.
Apache Hive
Hive is a data warehouse infrastructure built on top of Hadoop. It provides a SQL-like query language (HiveQL) and allows users to perform ad-hoc queries and analysis on the data stored in Hadoop.
Apache Spark
Spark is a distributed, fast and general-purpose cluster computing engine that provides in-memory data processing capabilities. It supports various data processing tasks such as batch processing, real-time streaming, machine learning, and graph processing.
Apache HBase
HBase is a distributed, scalable, and consistent NoSQL database that handle large amounts of structured data. It provides random read and write access to data stored in HDFS.
Apache Zookeeper
ZooKeeper is an open-source centralized coordination service that provides a reliable infrastructure for distributed systems. It offers a simple and robust way to manage and synchronize configuration information, naming services, and distributed locks in a distributed environment. ZooKeeper helps ensure consistency, reliability, and fault-tolerance in distributed applications by maintaining a consistent and up-to-date view of the system’s state.
Security components
Apache Knox
Knox serves as a secure gateway for Hadoop clusters and other big data systems. It acts as a reverse proxy, providing a unified entry point for accessing cluster resources. It offers features like identity federation, SSL/TLS encryption, authentication, and authorization mechanisms to safeguard the cluster from unauthorized access.
Apache Ranger
Apache Ranger is a comprehensive security framework designed for Apache Hadoop and other big data ecosystems. It provides centralized security administration and fine-grained access control to ensure data protection and privacy. With Ranger, administrators define and manage security policies, access control lists (ACLs), and role-based access control (RBAC). It offers advanced features like row-level filtering and dynamic data masking based on user permissions. Additionally, Ranger provides auditing and monitoring capabilities, enabling organizations to track user activities and maintain regulatory compliance.
Extra components
Apache Kafka
Kafka is an open-source distributed streaming platform that enables the efficient handling and processing of real-time data streams. It provides a high-throughput, fault-tolerant, and scalable solution for collecting, storing, and processing streaming data. Kafka simplifies the process of building data pipelines, enabling reliable data integration between different systems and applications.
Apache Hue
Hue is an open-source web-based interface that simplifies the management and interaction with Apache Hadoop ecosystem tools. It provides a user-friendly environment for accessing and working with various components such as HDFS, Hive, HBase, and more, allowing users to easily navigate and perform data processing, querying, and analysis tasks without requiring extensive command-line knowledge.
Jupyter Hub
JupyterHub is an open-source project that enables multi-user access to Jupyter notebooks. It provides a web-based interface for users to create and manage their own Jupyter notebook instances, allowing collaborative and interactive data analysis, visualization, and programming in various languages such as Python, R, and Julia.
Apache Livy
Livy is an open-source RESTful web service that facilitates the remote execution and management of Spark jobs. It provides a convenient interface for submitting, monitoring, and controlling Spark applications, supporting multiple programming languages.